Event Sourcing Snapshots
I got a relevant question on yesterdays post. How does the snapshot mechanism work?
The easiest way to reconstruct a historical state is to start with a clean database, maybe populated with static reference data, and then apply all events in order up to the point you are interested in. This will take forever if your system has been running for a while, it contains a lot of events.
The trick to make it work is to periodically take a snapshot of the complete database. When doing replay it can start with the preceding snapshot and only replay events after the snapshot time up to the time you are interested in.
Taking a snapshot can be implemented in various ways. I have tried an approach that aims at being able to take a snapshot without stopping/locking normal operation, i.e. inflow of events and processing of them can continue.
The steps to create snapshots are illustrated by the following figure. It also illustrates a query to replay events to a specific point in time.
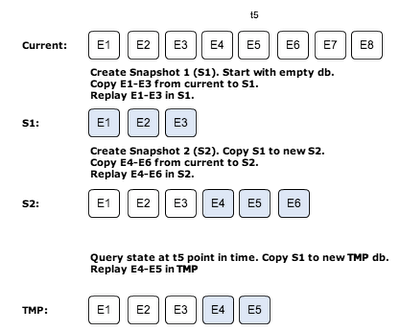
How do I copy database? For MongoDB there is a simple copydb command, which can be executed from the application. Exactly how to do this with other databases is vendor specific, but I guess it is possible somehow. At least in command line admin mode. Since I always copy from a read-only (snapshot) database it is should be a consistency safe operation.
These operations will of course not be super fast and temporary databases for historical queries must probably be prepared in advanced to have decent response times. If you need to do a lot of historical queries you need something more, such as a separate system responsible for answering such queries. It may be a data warehouse, a denormalized database, or whatever tailored for the purpose. This separate system is fed from the same original event stream. The design is called CQRS.
