MongoDB Tutorial
MongoDB bridges the gap between key-value stores (which are fast and highly scalable) and traditional RDBMS systems (which provide rich queries and deep functionality).
I think this makes MongoDB very interesting for applications that need high-performance and/or scalability, but also prefer using a rich persistent domain model with complex associations. There are of course tradeoffs to be aware of, such as relaxed transactional guarantees.
The schema-less structure is attractive from a developer productivity perspective, which is one of the two goals with Sculptor (quality is the other).
Before you start you need to run a mongoDB server locally. Therefore download and install mongoDB. Start mongoDB with bin/mongod command.
Table of Contents:
- Part 1 - Setup Project for Business Tier
- Part 2 - Business Tier Hands On
- Part 3 - Business Tier Explained
- Blog Posts
- Source
Part 1 - Setup Project for Business Tier
In this first part we will setup the project structure for Maven and Eclipse.
-
Use Sculptors Maven archetype with the following command (one line - indicated by the trailing
\) to create a new project with Maven POM and file structure. You can change the groupId and artifactId if you like.mvn archetype:generate -DarchetypeGroupId=org.sculptorgenerator \ -DarchetypeArtifactId=sculptor-maven-archetype \ -DarchetypeVersion=3.1.0 \ -Dstandalone=true \ -Dmongodb=trueThe property
-Dstandalone=trueindicates that the project is not part of a Maven multi-module project and is not refering to a common parent project.The property
-Dmongodb=trueindicates that this Sculptor Maven project needs some tweaks for supporting mongoDB, e.g. different dependendencies inpom.xmlor aditional settings in thesculptor-generator.propertiesfile.Fill in groupId and artifactId:
Define value for groupId: : org.blogger Define value for artifactId: : blog Define value for version: 1.0-SNAPSHOT: : Define value for package: org.blogger: : -
Open Eclipse and import the project via (via m2e Eclipse plugin) with “File > Import… > Existing Maven Projects”.
-
Create an Eclipse m2e launch configuration for executing Maven (e.g. with the goal
generate-sources) from within Eclipse (right-clicking the project or Maven POM and selecting “Run as > Maven build…” from the context menu).To refresh the Eclipse workspace after Sculptors code generator created new code enable the option “Refresh > Refresh resources upon completion > The project containing the selected resource” in the launch configuration.
Before you start serious development you should follow the instructions in the Installation Guide.
Part 2 - Business Tier Hands On
In this part we will write a Sculptor DSL file and generate code from it.
-
Modify the file named
model.btdesignin the foldersrc/main/resources/ -
Open the
model.btdesignfile with Sculptor DSL editor, double-click on it. Add the following to the design file.Application Blog { basePackage = org.blog Module core { Entity BlogPost { scaffold - Blog inBlog String slug key String title String body length="2000" Date published nullable - Author writtenBy - Set<Comment> comments def List<Comment> getSortedComments; Repository BlogPostRepository { List<@BlogPost> findPostsInBlog(@Blog inBlog); List<@BlogPost> findPostsWithComments => AccessObject; List<@BlogPost> findPostsWithGreatComments; protected findByCondition; } } ValueObject Comment { not aggregateRoot String title String body Timestamp timestamp } Entity Blog { scaffold String ^url key String title String intro length="300" - Set<Author> writers } Entity Author { scaffold String name required String emailAddress } } }Visualization of this model looks like this (generated by Sculptor):
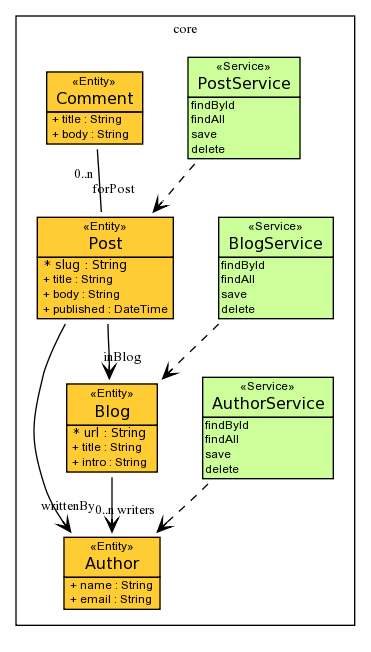
-
Run
mvn clean installto generate code and build. The JUnit test will fail.If you run Maven from the command prompt you have to refresh the Eclipse workspace. If you from within Eclipse with the aforementioned m2e launch configuration then the workspace is refreshed automatically.
-
Now it is your task to complete the failing tests. A start for implementing
AuthorServiceTestmay look like this:private String authorId1; @Before public void initTestData() { Author author1 = new Author("Patrik"); Author saved = authorService.save(SimpleJUnitServiceContextFactory.getServiceContext(), author1); authorId1 = saved.getId(); } @Test public void testFindById() throws Exception { Author found = authorService.findById(SimpleJUnitServiceContextFactory.getServiceContext(), authorId1); assertEquals("Patrik", found.getName()); }You need to run a mongoDB server locally. Therefore download and install mongoDB. Start mongoDB with
bin/mongodcommand.When running the tests it will connect to a mongoDB instance running at localhost (default port 27017). The database will be created automatically and dropped after each test method (done by the
@After dropDatabasemethod in the test case).
Part 3 - Business Tier Explained
Most things that can be done with JPA target implementation can also be done with mongoDB. Therefore most of the descriptions in Advanced Tutorial are valid and I will not repeat everything, but I will elaborate on some topics.
Activation
To activate Sculptors mongoDB support the following properties are needed in the sculptor-generator.properties file (already set by the Sculptor Maven archetype).
nosql.provider=mongoDb
cartridges=builder,mongodb
The property cartridges is used to enable a (comma-separated) list of extensions used by Sculptors internal template override mechanismus.
- The extension ‘builder’ generates a builder class for each domain object.
- The extension
mongoDBmodifies the default templates in order to add the mongoDB support.
Associations
An associated object can be stored as an embedded document, i.e. it belongs to parent object and cannot be shared between several objects. References to BasicType are always embedded. Aggregates are also embedded in the DBCollection of the parent object. Aggregates are defined with belongsTo or not aggregateRoot in the owned DomainObjects.
Entity Cargo {
- TrackingId trackingId key;
- Location origin required;
- Location destination required;
- Itinerary itinerary nullable opposite cargo;
- Set<HandlingEvent> events opposite cargo;
}
BasicType TrackingId {
String identifier key
}
ValueObject Itinerary {
belongsTo Cargo
- Cargo cargo nullable opposite itinerary
- List<Leg> legs
}
ValueObject Leg {
belongsTo Cargo
- CarrierMovement carrierMovement
- Location from
- Location to
}
In above sample the TrackingId, Itinary and Leg are all stored toghether with the Cargo.
The other alternative is to store ids of the referred objects. Associations that are not owned are treated in this way. In the above sample the references to Location and HandlingEvent are unowned. In the domain objects there are generated getters that lazily fetch associated objects from the ids. This means that you don’t have to work with the ids yourself, you can follow associations as usual, but be aware that an invocation of such a getter might need to query the database.
Referential integrity is not enforced. It must be handled by your program. Lazy getters of associations will not fail if referred to object is missing, they will return null for single value references and ignore missing objects for collection references. This means that you can cleanup dangling references by fetching objects, populate associations by invoking the getters and then save the object. There is also a populateAssociations repository operation to fetch all referred objects.
Avoid bidirectional associations Within an aggregate it is not possible to use bidirectional associations or associations that creates cycles. Bidirectional associations cross aggregates are possible but complicated, because one end must be saved first, and the assignment of the id is done after the object is saved.
Data Mapper
When working with mongoDB Java API the DBObject plays a central role. It is like a key-value Map. Values can be of most types and also collections and other DBObjects for nested documents.
Sculptor generates data mapper classes that converts domain objects to DBObjects. It is useful to not have to write those mappers by hand. Since it is generated code it also runs at full speed, compared to alternative solutions using reflection or intermediate String JSON format.
You might need to add some hand written code to customize to the mappers. That is easy. Add hint="gapMapper" and you will have a subclass that you can implement yourself. This is very useful for doing data migration. In the model:
Entity Person {
hint="gapMapper"
Date birthDate
- Gender sex !changeable
- Ssn ssn key
- PersonName name
}
In the Java class PersonMapper:
@Override
public Person toDomain(DBObject from) {
if (from == null) {
return null;
}
// converting from old name structure to new
if (!from.containsField("name") && from.containsField("firstName") && from.containsField("lastName")) {
BasicDBObject name = new BasicDBObject();
name.put("first", from.get("firstName"));
name.put("last", from.get("lastName"));
from.put("name", name);
}
return super.toDomain(from);
}
@Override
public DBObject toData(Person from) {
return super.toData(from);
}
It can also be good to know that fields marked with transient are are not stored, but they are loaded if they exist in the retrieved documents. This can also be used for data migration.
requestStart / requestDone
To ensure that you read your own writes MongoDB java driver recommends using requestStart() / requestDone(). This is done by the DbManagerAdvice, which is automatically added in front of services. This is also necessary for optimistic locking.
Optimistic Locking
By default a version attribute is automatically added to each Entity and mutable persistent ValueObject. This is used for optimistic locking checks. You can skip this feature by specifying !optimisticLocking for the Domain Object.
Index
Indexes are defined and created automatically for the natural key fields, i.e. attributes and references marked with key. It is possible to define additional indices for attributes by marking them with index.
The id field (database primary key) is always indexed.
In the following sample there will be one composite index for ssn.number, ssn.country and another index for birthDate.
Entity Person {
gap
hint="gapMapper"
Date birthDate index
- Gender sex !changeable
- Ssn ssn key
- PersonName name
}
BasicType Ssn {
String number key length="20"
- @Country country key
}
Indexes are defined in the generated method indexes in the mapper. It is possible for you to override this method and manually adjust the indices or add more indexes.
Repositories
Sculptor provides the following generic repository operations for use with mongoDB:
findByIdfindAllfindByConditionfindByKeyfindByKeyssavedeletecountAllpopulateAssociations
findByCondition
mongoDB has good support for dynamic queries on any attribute. The easiest way to create a query is to use findByCondition, which is one of the built in repository operations.
In model.btdesign:
Repository BlogPostRepository {
List<@BlogPost> findPostsWithGreatComments;
protected findByCondition;
}
The hand written Java implementation:
import static org.blog.core.domain.BlogPostProperties.*;
import static org.sculptor.framework.accessapi.ConditionalCriteriaBuilder.*;
public List<BlogPost> findPostsWithGreatComments() {
List<ConditionalCriteria> condition = criteriaFor(BlogPost.class)
.withProperty(comments().title()).ignoreCaseLike(".*great.*")
.and().withProperty(published()).isNotNull()
.orderBy(published()).build();
return findByCondition(condition);
}
The ConditionalCriteriaBuilder builder supports conditions such as eq, like, between, lessThan, greaterThan and in. The order of the result can be specified with orderBy. Regular expression condition can be defined with like and ignoreCaseLike (ignore case).
Limitations of findByCondition when used with mongoDB:
- It is not possible to specifiy criteria on attibutes of unowned associations.
- OR-condition is not supported.
Pagination
Pagination is supported as described in Advanced Tutorial
Generation of Finder Operations
Generated finder methods, based on findByCondition, is supported as described in Advanced Tutorial. It has the same limitations as findByCondition when used with mongoDB, described above.
Example of generated finders in the BlogPostRepository:
Repository BlogPostRepository {
findByTitle(String title) condition="title i= :title";
findPostsInBlog(@Blog blog) orderBy="title";
}
Note that this feature is not activated by default. To allow sculptor to generate finder operations add the following line into your sculptor-generator.properties file.
generate.repository.finders=true
After activation all repository operations starting with ‘find’, except built in operations, are potential candidates for finder generation. To prevent a generation and to use handwritten code for a special operation, add the keyword ‘gap’.
PersonRepository {
List<@Person> findPersonByName(String name) gap;
}
Own AccessObject
You can also easily create your own Access Object (as described in the Advanced Tutorial) with full access to the underlaying DBCollection.
For example, a query that finds blog posts with comments. In model.btdesign:
Repository BlogPostRepository {
List<@BlogPost> findPostsWithComments => AccessObject;
}
You write the implementation yourself and it may look something like this:
public class FindPostsWithCommentsAccessImpl extends FindPostsWithCommentsAccessImplBase {
@Override
public void performExecute() {
DBObject query = new BasicDBObject();
query.put("comments", new BasicDBObject("$not", new BasicDBObject("$size", 0)));
DBCursor cursor = getDBCollection().find(query);
List<BlogPost> mappedResult = new ArrayList<BlogPost>();
for (DBObject each : cursor) {
BlogPost eachResult = (BlogPost) getDataMapper().toDomain(each);
mappedResult.add(eachResult);
}
setResult(mappedResult);
}
}
MongoDB specific code directly in Repository
The default implementation of a Repository consists of an implementation class and Access Objects. The intention is a separation of concerns between the domain and the data layer. Repository is close to the business domain and Access Objects are close to the data layer. The MongoDB specific code is located in the Access Object, and not in the Repository.
For some systems this separation might be overkill and you might prefer to implement the data access directly in the Repository. Sculptor supports this design out-of-the-box. You only have to specify a property in sculptor-generator.properties to have MongoDB support directly in the Repository implementation. The starting point is the method getDbManager.
generate.repository.dbManagerSupport=true
MongoDB documentation
Documentation of queries: http://www.mongodb.org/display/DOCS/Querying
Configuration
It is possible to define configuration options for the MongoDB connection. It is done in spring.properties. You find available configuration parameters (default values) in generated-spring.properties. Documentation of options is here. Example:
mongodb.dbname=Blog
mongodb.url1=localhost:27017
mongodb.url2=otherhost:27017
mongodbOptions.connectionsPerHost=10
When running JUnit test the dbname is suffixed with -test.
Custom Datastore Names
By default the names in the data store are the same as the names in the Java DomainObjects. In case you need to use other names it is possible to define that in model with databaseTable and databaseColumn. Discriminator name and value is also possible to define when inheritance is used.
abstract Entity Media {
databaseTable="Products"
discriminatorColumn="type"
String title !changeable
}
Entity Book extends @Media {
discriminatorValue="B"
String isbn key length="20" databaseColumn="KEY"
}
Entity Movie extends @Media {
discriminatorValue="M"
String urlIMDB key databaseColumn="KEY"
Integer playLength
}
Blog Posts
In the Sculptor Blog there’s a series of posts related to mongoDB.
Source
The complete source code for this tutorial is available in GitHub https://github.com/sculptor/sculptor/tree/master/sculptor-examples/mongodb-samples/blog-mongodb.
